Please don't leave just yet, because I know that there are tons of PDF merging software and websites out there. So why did I consider this project into my portfolio. Hear me out first, it was a chance to try out my skills to create an application to solve this little problem. Using tkinter, specially Customtkinter from Tom Schimansky and PyPDF2, I wanted to customize my very own PDF merger application and share it to others in my office.
As the date of the code pushed into GitHub, that was the first version of my simple application. I will talk about more on scaling it in near future later.
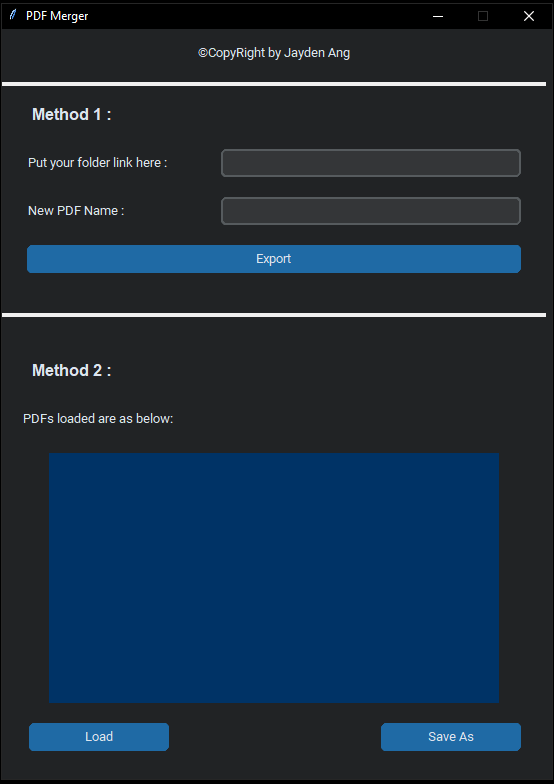
First version of the application; top and bottom section for different methods
This application is aimed to solve a problem which is to merge multiple single-page PDFs into 1 multipage PDF in order to be printed with double-sided. I didn't want to use online websites solution because the documents are confidential. And the existing apps are maybe malicious during downloading or putting a watermark in it after merging. Making my own application can allow me to design it to my own taste and fit my requirement.
Version 1 of the application is having 2 textboxes to get input from users. First input is the path of the folder which contents all and only the PDFs that user wants to merge. Second input is to get the name of the new PDF file that is merged. The function mergepdf() will walk through the folder and look for all files that ends with .pdf extension. These file will be temporarily appended into a list and pass on to the PdfFileReader object by PyPDF2. Then the new object will append into the new file name .pdf and save it in the same folder. There is a try & exception where if user does not provide a path, the function does not work.
Initial impressions by potential users are that the step to create a directory just to make a merged PDF is too tidious. Hence, the code was rewrite into the second version. In version 2, user can load the PDF through a browsing window from different directories. There will be a display of the PDFs that been loaded. Once they are done loading, they can click save as button to select the location of where they want to save the new file and provide a new file name just like saving any documents from window.
For now, this version is sufficient to tackle my initial problem statement. So I have leaved it as it is and package it to others. Using auto_py_to_exe, I compiled the neccesary dependencies into a ZIP file for deployment. However, I am not particularly satisfied with the whole interface and user experience.
Hence, I have several thoughts in mind to further improve it once I have some time. First improvement will be: add a couple more functionalilty into the application. One of them is to manipulate with the PDFs that been loaded using method 2. Refering to CRUD, the application can create new pdf files into memory, read them to merge into a file, so next will be deleting the loaded pdf if accidentally loaded the wrong ones. And finally, update will be refering to the page sequence of the loaded PDFs.
Another improvement is, since more functionality has been added, the graphical interface should be updated accordingly. I wanted a column of tabs on the left side of the application window to display the related interface for user depending on the method been selected.
The improvement has not been done as of 13th Aug 2022.
Update on 15th Aug 2022. The second improvement mentioned above had been done. There are two tabs on the left side of the GUI to be chosen between 2 methods. Top method will be displayed by default. The rest of the application function works just the same as previous.
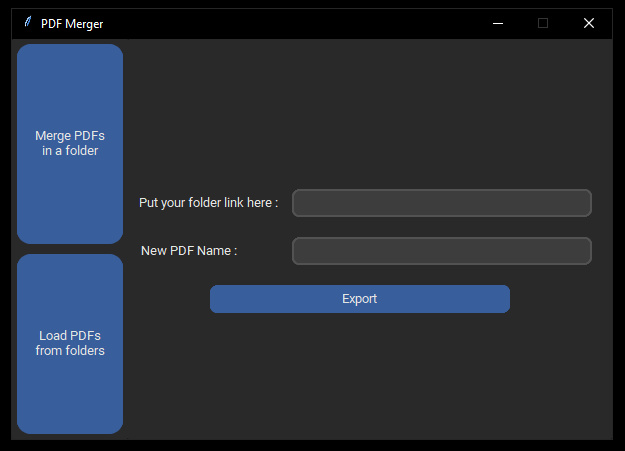
Second version of the application; one of the methods
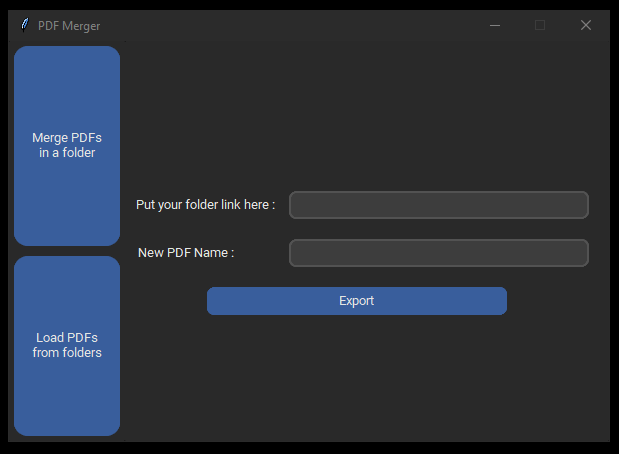
Second version of the application; another one of the methods